本文在的理论基础上,进一步分析一个实际的 ORC表中的数据存储形式。
一、表结构
库名+表名:fileformat.test_orc
| 字段 | 类型 |
|---|---|
| category_id | string |
| product_id | int |
| brand_id | int |
| price | double |
| category_id_2 | string |
在hive中命令
desc formatted fileformat.test_orc;的结果如下图: 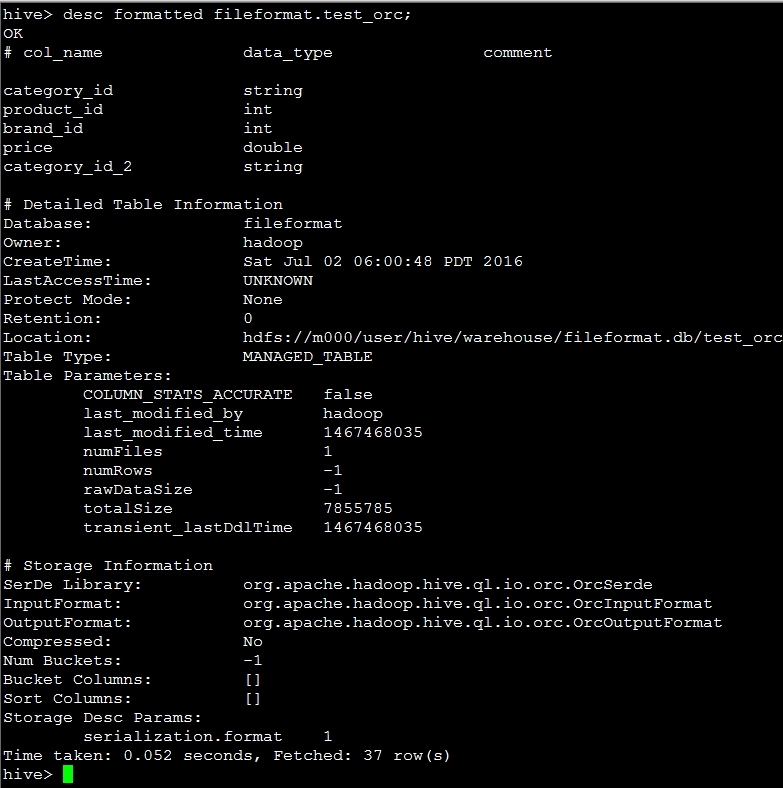 根据上图中的location信息,查看在HDFS上的文件:
根据上图中的location信息,查看在HDFS上的文件: 
二、查看dump文件
hive提供了一个--orcfiledump参数用于查看HDFS上ORC表格的文件信息,在hive-0.13版本中的使用方法为:hive --orcfiledump <location-of-orc-file>,其他版本的使用方法可以去官方文档中查找。
hive --orcfiledump /user/hive/warehouse/fileformat.db/test_orc/000000_0的查询结果 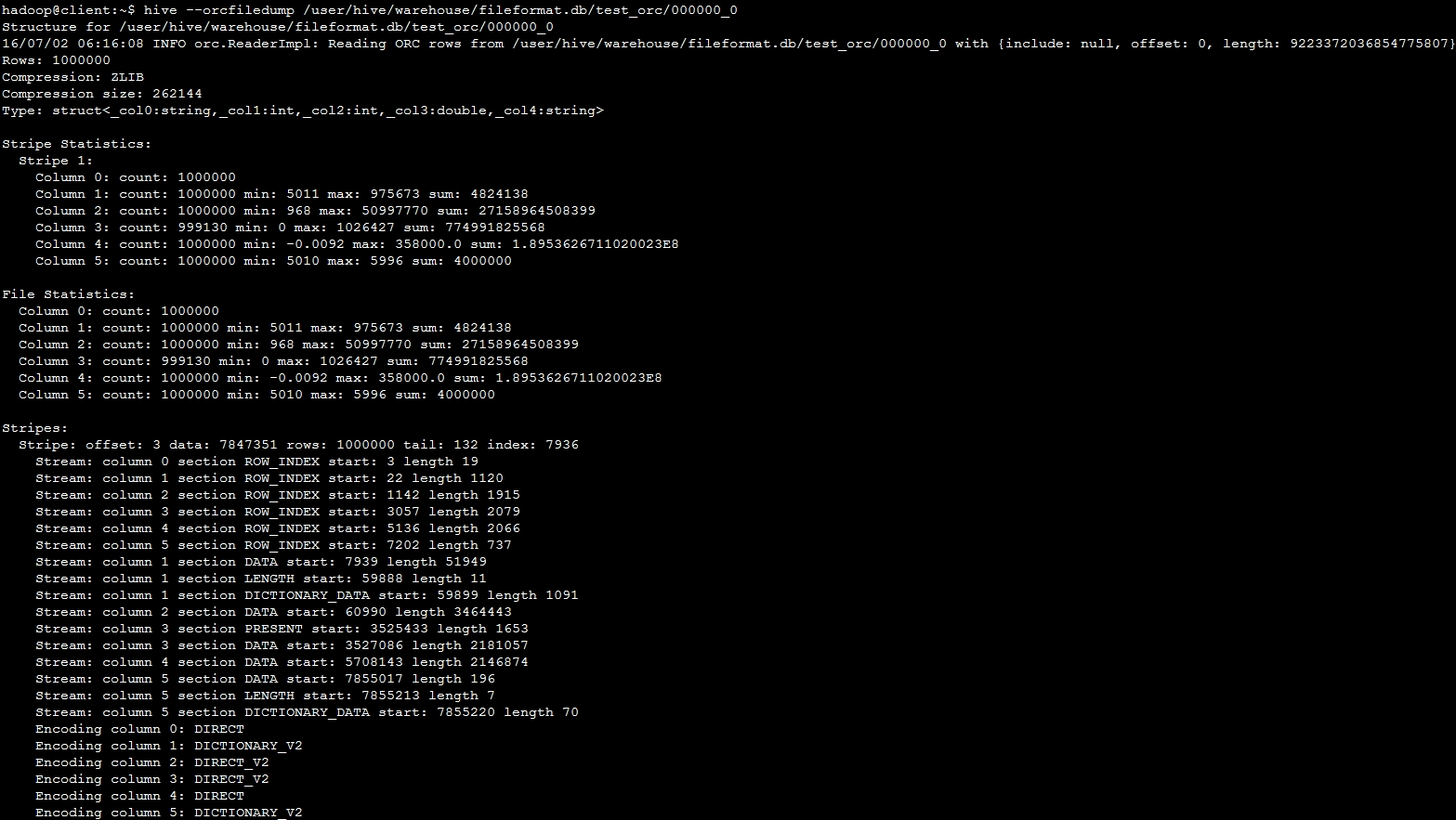
三、dump文件分析
接下来的分析,请对照着文章中的图1-ORC文件结构图进行。
使用hql语句,统计出各字段的count, min, max, sum信息如下:| 字段 | COUNT | MIN | MAX | SUM |
|---|---|---|---|---|
| category_id | 1000000 | 5011 | 975673 | 4.0222868968E11 |
| product_id | 1000000 | 968 | 50997770 | 27158964508399 |
| brand_id | 999130 | 0 | 1026427 | 774991825568 |
| price | 1000000 | -0.0092 | 358000.0 | 1.8953626711045265E8 |
| category_id_2 | 1000000 | 5010 | 5996 | 5.183530839E9 |
从dump文件的图片中可以看出,大致分成四个部分:
1、表结构信息
记录整张表的记录数,压缩方式,压缩大小,以及表结构。在表结构部分,ORC将整张表的所有字段构造成一个大的struct结构。对应图1-ORC文件结构图中的Postscript部分。
2、Stripe统计信息
统计当前HDFS文件对应Stripe的信息,包括各个字段的count,min, max, sum信息。对于最外层的Struct,只统计其count值。由于这张表数据量不大,当前HDFS文件中只有一个Stripe。对应图1-ORC文件结构图中的Stripe Footer部分。
3、File统计信息
统计内容和第二部分一致,不过这里统计的整张表的每个字段count, min, max, sum信息。对应图1-ORC文件结构图中的FileFooter部分。
这里我们将dump文件中的统计信息,与各字段实际统计信息作对比。通过与上面表格中各字段统计信息对比,发现对于int类型和double类型的字段,min, max, sum的结果都是匹配的。但是对于string类型的字段,仅仅只有min, max统计结果一致,sum的结果不相同。4、Stripe详细信息
统计各Stripe的offset,总记录行数等Stripe层次的信息。该Stripe中各字段的Index Data和Row Data,以及每个字段的编码方式。
前面一行Stripe: offset: 3 data: 7847351 rows: 1000000 tail: 132 index: 7936应该也是保存在FileFooter中,后面各个字段统计信息对应图1-ORC文件结构图中的Index Data和Row Data部分。 从dump文件中的数据可以看出,每个字段的ROW_INDEX以及DATA信息是保存在一块连续空间中的,这块文件从offset=3开始。这也说明图1-ORC文件结构图中Row Data区的数据紧随Index Data区数据之后。 Index Data数据统计:| 起始位置 | 字段 |
|---|---|
| 3……21 | STRUCT |
| 22……1141 | category_id |
| 1142……3056 | product_id |
| 3057……5135 | brand_id |
| 5136……7201 | price |
| 7202……7938 | category_id_2 |
Row Data数据统计:
| 起始位置 | 字段 | 描述 |
|---|---|---|
| 7939……59887 | category_id | 字段对应词条int流 |
| 59888……59898 | category_id | 词条长度int流 |
| 59899……60989 | category_id | 字典词条数据 |
| 60990……3525432 | product_id | 实际数据int流 |
| 3525433……3527085 | brand_id | 标识IF NULL的byte流 |
| 3527086……5708142 | brand_id | 实际数据int流 |
| 5708143……7855016 | price | double类型 |
| 7855017……7855212 | category_id_2 | 字段对应词条int流 |
| 7855213……7855219 | category_id_2 | 词条长度int流 |
| 7855220……7855289 | category_id_2 | 字典词条数据 |
在ORC文件的int类型和string类型保存时,会有一个byte流用于记录字段的某个记录是否为null,根据统计只有brand_id 字段的count值不足100000条,也就是说除了brand_id 字段之外,其他字段中没有null值。所以在上面Row Data表中,只有brand_id有一个对应的IF NULL标识流。一个String类型,会将词条数据保存在字节流中,然后一个int流记录每个词条的长度,另外一个int流用于指定字段某个记录对应字典词条中的哪一个。
这部分最后记录了每一个字段的存储方式,统计如下
| 字段 | 类型 | 存储方式 |
|---|---|---|
| STRUCT | DIRECT | |
| category_id | String | DICTIONARY_V2 |
| product_id | Int | DIRECT_V2 |
| brand_id | Int | DIRECT_V2 |
| price | Double | DIRECT |
| category_id_2 | String | DICTIONARY_V2 |